Interpretability
[1]:
from molgraph.chemistry import MolecularGraphEncoder
from molgraph.chemistry import Featurizer
from molgraph.chemistry import features
from molgraph.models import GradientActivationMapping
from molgraph.models import IntegratedSaliencyMapping
import tensorflow as tf
import numpy as np
import pandas as pd
np.set_printoptions(suppress=True)
Construct a MolecularGraphEncoder
[2]:
atom_encoder = Featurizer([
features.Symbol({'C', 'N', 'O'}, oov_size=1),
features.Hybridization({'SP', 'SP2', 'SP3'}, oov_size=1),
features.HydrogenDonor(),
features.HydrogenAcceptor(),
features.Hetero()
])
bond_encoder = Featurizer([
features.BondType({'SINGLE', 'DOUBLE', 'TRIPLE', 'AROMATIC'}),
features.Rotatable()
])
mol_encoder = MolecularGraphEncoder(atom_encoder, bond_encoder, positional_encoding_dim=None)
mol_encoder
[2]:
MolecularGraphEncoder(atom_encoder=Featurizer(features=[Symbol(allowable_set=['[OOV:0]', 'C', 'N', 'O'], ordinal=False, oov_size=1), Hybridization(allowable_set=['[OOV:0]', 'SP', 'SP2', 'SP3'], ordinal=False, oov_size=1), HydrogenDonor(), HydrogenAcceptor(), Hetero()]), bond_encoder=Featurizer(features=[BondType(allowable_set=['AROMATIC', 'DOUBLE', 'SINGLE', 'TRIPLE'], ordinal=False, oov_size=0), Rotatable()]), positional_encoding_dim=None, self_loops=False)
Obtain dataset
[3]:
path = tf.keras.utils.get_file(
fname='ESOL.csv',
origin='http://deepchem.io.s3-website-us-west-1.amazonaws.com/datasets/ESOL.csv',
)
df = pd.read_csv(path)
df.head(3)
[3]:
| Compound ID | ESOL predicted log solubility in mols per litre | Minimum Degree | Molecular Weight | Number of H-Bond Donors | Number of Rings | Number of Rotatable Bonds | Polar Surface Area | measured log solubility in mols per litre | smiles | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Amigdalin | -0.974 | 1 | 457.432 | 7 | 3 | 7 | 202.32 | -0.77 | OCC3OC(OCC2OC(OC(C#N)c1ccccc1)C(O)C(O)C2O)C(O)... |
| 1 | Fenfuram | -2.885 | 1 | 201.225 | 1 | 2 | 2 | 42.24 | -3.30 | Cc1occc1C(=O)Nc2ccccc2 |
| 2 | citral | -2.579 | 1 | 152.237 | 0 | 0 | 4 | 17.07 | -2.06 | CC(C)=CCCC(C)=CC(=O) |
Obtain SMILES xand associated labels y
[4]:
x, y = df['smiles'].values, df['measured log solubility in mols per litre'].values
Obtain GraphTensor from x
[5]:
x_data = mol_encoder(x)
print(x_data, end='\n\n')
print('node_feature shape:', x_data.node_feature.shape)
print('edge_dst shape: ', x_data.edge_dst.shape)
print('edge_src shape: ', x_data.edge_src.shape)
print('edge_feature shape:', x_data.edge_feature.shape)
GraphTensor(
sizes=<tf.Tensor: shape=(1128,), dtype=int64>,
node_feature=<tf.Tensor: shape=(14991, 11), dtype=float32>,
edge_src=<tf.Tensor: shape=(30856,), dtype=int32>,
edge_dst=<tf.Tensor: shape=(30856,), dtype=int32>,
edge_feature=<tf.Tensor: shape=(30856, 5), dtype=float32>)
node_feature shape: (14991, 11)
edge_dst shape: (30856,)
edge_src shape: (30856,)
edge_feature shape: (30856, 5)
1. Build Keras GNN model with GNN layers
[34]:
from molgraph.layers import GCNConv, Readout
sequential_model = tf.keras.Sequential([
tf.keras.layers.Input(type_spec=x_data.spec),
GCNConv(128, name='conv_1'),
GCNConv(128, name='conv_2'),
GCNConv(128, name='conv_3'),
GCNConv(128, name='conv_4'),
Readout(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1)
])
sequential_model.summary()
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv_1 (GCNConv) (None, None, 128) 4608
conv_2 (GCNConv) (None, None, 128) 33152
conv_3 (GCNConv) (None, None, 128) 33152
segment_pooling_readout_6 (None, 128) 0
(SegmentPoolingReadout)
dense_12 (Dense) (None, 512) 66048
dense_13 (Dense) (None, 1) 513
=================================================================
Total params: 137473 (537.00 KB)
Trainable params: 137473 (537.00 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
2. Compile and fit GNN model
[35]:
sequential_model.compile('adam', 'mse', ['mae'])
sequential_model.fit(x_data, y, epochs=50, verbose=2);
Epoch 1/50
36/36 - 3s - loss: 4.2682 - mae: 1.6230 - 3s/epoch - 84ms/step
Epoch 2/50
36/36 - 0s - loss: 3.3620 - mae: 1.4817 - 179ms/epoch - 5ms/step
Epoch 3/50
36/36 - 0s - loss: 3.3828 - mae: 1.4810 - 188ms/epoch - 5ms/step
Epoch 4/50
36/36 - 0s - loss: 3.1614 - mae: 1.4371 - 186ms/epoch - 5ms/step
Epoch 5/50
36/36 - 0s - loss: 2.9661 - mae: 1.3852 - 183ms/epoch - 5ms/step
Epoch 6/50
36/36 - 0s - loss: 2.8416 - mae: 1.3507 - 188ms/epoch - 5ms/step
Epoch 7/50
36/36 - 0s - loss: 2.7258 - mae: 1.3335 - 176ms/epoch - 5ms/step
Epoch 8/50
36/36 - 0s - loss: 2.5141 - mae: 1.2632 - 186ms/epoch - 5ms/step
Epoch 9/50
36/36 - 0s - loss: 2.6962 - mae: 1.2898 - 186ms/epoch - 5ms/step
Epoch 10/50
36/36 - 0s - loss: 2.5491 - mae: 1.2679 - 180ms/epoch - 5ms/step
Epoch 11/50
36/36 - 0s - loss: 2.3768 - mae: 1.2089 - 180ms/epoch - 5ms/step
Epoch 12/50
36/36 - 0s - loss: 2.3904 - mae: 1.2302 - 177ms/epoch - 5ms/step
Epoch 13/50
36/36 - 0s - loss: 2.1581 - mae: 1.1444 - 185ms/epoch - 5ms/step
Epoch 14/50
36/36 - 0s - loss: 2.4210 - mae: 1.2226 - 187ms/epoch - 5ms/step
Epoch 15/50
36/36 - 0s - loss: 2.2568 - mae: 1.1956 - 197ms/epoch - 5ms/step
Epoch 16/50
36/36 - 0s - loss: 2.1405 - mae: 1.1333 - 201ms/epoch - 6ms/step
Epoch 17/50
36/36 - 0s - loss: 1.9765 - mae: 1.0873 - 203ms/epoch - 6ms/step
Epoch 18/50
36/36 - 0s - loss: 1.9263 - mae: 1.0707 - 204ms/epoch - 6ms/step
Epoch 19/50
36/36 - 0s - loss: 1.9688 - mae: 1.0793 - 186ms/epoch - 5ms/step
Epoch 20/50
36/36 - 0s - loss: 1.8725 - mae: 1.0718 - 170ms/epoch - 5ms/step
Epoch 21/50
36/36 - 0s - loss: 1.9170 - mae: 1.0576 - 176ms/epoch - 5ms/step
Epoch 22/50
36/36 - 0s - loss: 1.9656 - mae: 1.0912 - 181ms/epoch - 5ms/step
Epoch 23/50
36/36 - 0s - loss: 1.7675 - mae: 1.0313 - 185ms/epoch - 5ms/step
Epoch 24/50
36/36 - 0s - loss: 1.7883 - mae: 1.0274 - 172ms/epoch - 5ms/step
Epoch 25/50
36/36 - 0s - loss: 1.9393 - mae: 1.0915 - 182ms/epoch - 5ms/step
Epoch 26/50
36/36 - 0s - loss: 1.7453 - mae: 1.0155 - 179ms/epoch - 5ms/step
Epoch 27/50
36/36 - 0s - loss: 1.7054 - mae: 1.0131 - 182ms/epoch - 5ms/step
Epoch 28/50
36/36 - 0s - loss: 1.7013 - mae: 1.0174 - 179ms/epoch - 5ms/step
Epoch 29/50
36/36 - 0s - loss: 1.7120 - mae: 1.0070 - 179ms/epoch - 5ms/step
Epoch 30/50
36/36 - 0s - loss: 1.7977 - mae: 1.0334 - 180ms/epoch - 5ms/step
Epoch 31/50
36/36 - 0s - loss: 1.6766 - mae: 0.9960 - 186ms/epoch - 5ms/step
Epoch 32/50
36/36 - 0s - loss: 1.6374 - mae: 0.9735 - 180ms/epoch - 5ms/step
Epoch 33/50
36/36 - 0s - loss: 1.6437 - mae: 0.9936 - 180ms/epoch - 5ms/step
Epoch 34/50
36/36 - 0s - loss: 1.5678 - mae: 0.9722 - 184ms/epoch - 5ms/step
Epoch 35/50
36/36 - 0s - loss: 1.4954 - mae: 0.9241 - 179ms/epoch - 5ms/step
Epoch 36/50
36/36 - 0s - loss: 1.5489 - mae: 0.9540 - 175ms/epoch - 5ms/step
Epoch 37/50
36/36 - 0s - loss: 1.4601 - mae: 0.9223 - 183ms/epoch - 5ms/step
Epoch 38/50
36/36 - 0s - loss: 1.5156 - mae: 0.9418 - 176ms/epoch - 5ms/step
Epoch 39/50
36/36 - 0s - loss: 1.5280 - mae: 0.9391 - 178ms/epoch - 5ms/step
Epoch 40/50
36/36 - 0s - loss: 1.5135 - mae: 0.9387 - 179ms/epoch - 5ms/step
Epoch 41/50
36/36 - 0s - loss: 1.4961 - mae: 0.9250 - 181ms/epoch - 5ms/step
Epoch 42/50
36/36 - 0s - loss: 1.4935 - mae: 0.9296 - 176ms/epoch - 5ms/step
Epoch 43/50
36/36 - 0s - loss: 1.4748 - mae: 0.9282 - 179ms/epoch - 5ms/step
Epoch 44/50
36/36 - 0s - loss: 1.4566 - mae: 0.9082 - 170ms/epoch - 5ms/step
Epoch 45/50
36/36 - 0s - loss: 1.3972 - mae: 0.9027 - 186ms/epoch - 5ms/step
Epoch 46/50
36/36 - 0s - loss: 1.4849 - mae: 0.9236 - 176ms/epoch - 5ms/step
Epoch 47/50
36/36 - 0s - loss: 1.3397 - mae: 0.8696 - 183ms/epoch - 5ms/step
Epoch 48/50
36/36 - 0s - loss: 1.4117 - mae: 0.8968 - 172ms/epoch - 5ms/step
Epoch 49/50
36/36 - 0s - loss: 1.2797 - mae: 0.8465 - 177ms/epoch - 5ms/step
Epoch 50/50
36/36 - 0s - loss: 1.2962 - mae: 0.8538 - 179ms/epoch - 5ms/step
3. Pass GNN model to GradientActivationMapping
[36]:
gam_model = GradientActivationMapping(
sequential_model,
['conv_1', 'conv_2', 'conv_3', 'conv_4'],
output_activation=None,
discard_negative_values=False,
)
gam = gam_model(x_data.separate())
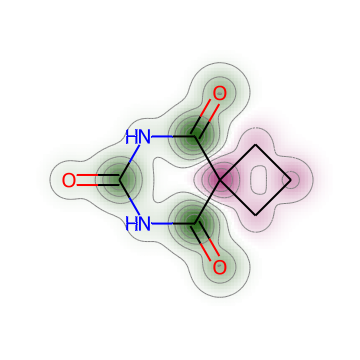
4. Visualize maps on molecule
[9]:
from molgraph.chemistry import vis
vis.visualize_maps(molecule=x[42], maps=gam[42])
[9]: